Machine Learning - O que é?
Por: ronaldo.chicareli@matera.com
Você já deve ter ouvido o termo Machine Learning (ou Aprendizagem de Máquina, em português, embora o termo em inglês seja muito mais comum).
Mas o que é isso exatamente?
Imagine que você possui vários emails e precisa ser capaz de definir se este email é spam ou não.
Olhando para os detalhes de emails antigos que você possui, é possível enumerar algumas características, conforme tabela abaixo. Esta tabela foi criada com 3 características fictícias apenas para facilitar a explicação.
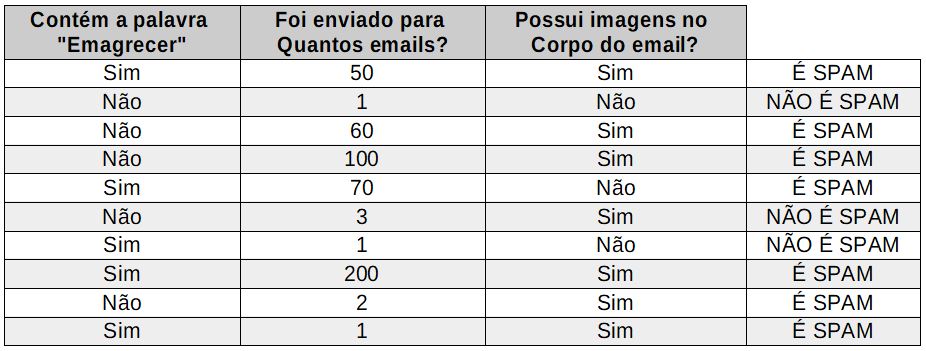 Figura 1 - Dados históricos de emails já classificados em SPAM e NÃO SPAM
Analisando este conjunto de dados, é possível perceber que a grande maioria dos emails com a palavra "Emagrecer" eram SPAM. Normalmente emails que eram enviados para mais de 10 destinatários também eram SPAM. Possuir imagens no corpo do email acaba sendo indiferente.
Então é possível tentar prever se um email é spam ou não.
É exatamente isso que os algoritmos de Machine Learning fazem.
A partir de dados históricos (vários emails recebidos e que já foram classificados em SPAM ou NÃO SPAM) é possível aplicar um algoritmo que tenta extrair regras destes dados, criando um modelo. Chamamos essa etapa de TREINAR o modelo.
Pegamos um novo email então e aplicamos o modelo criado, gerando uma possível classificação. Chamamos essa etapa de PREVER resultados.
Normalmente, não usamos todos os dados históricos para treinar o modelo
O ideal é dividir o conjunto de dados históricos em 2 grupos: 70% e 30% (ou 90% e 10%, ou o que for melhor para o seu negócio).
Usa-se 70% dos dados para treinar o modelo e os outros 30% são aplicados ao modelo gerado, de forma a verificar se a classificação prevista por ele realmente é a classificação correta. Dessa forma podemos verificar se o modelo tende a funcionar para dados desconhecidos. Essa etapa de validação chamamos de TESTAR o modelo.
Imagine que os 30% de dados no nosso caso correspondem a 10 emails. Se desses 10, o modelo acertou 9, então podemos dizer que a confiabilidade do modelo é de 90%.
Resumindo:
Figura 1 - Dados históricos de emails já classificados em SPAM e NÃO SPAM
Analisando este conjunto de dados, é possível perceber que a grande maioria dos emails com a palavra "Emagrecer" eram SPAM. Normalmente emails que eram enviados para mais de 10 destinatários também eram SPAM. Possuir imagens no corpo do email acaba sendo indiferente.
Então é possível tentar prever se um email é spam ou não.
É exatamente isso que os algoritmos de Machine Learning fazem.
A partir de dados históricos (vários emails recebidos e que já foram classificados em SPAM ou NÃO SPAM) é possível aplicar um algoritmo que tenta extrair regras destes dados, criando um modelo. Chamamos essa etapa de TREINAR o modelo.
Pegamos um novo email então e aplicamos o modelo criado, gerando uma possível classificação. Chamamos essa etapa de PREVER resultados.
Normalmente, não usamos todos os dados históricos para treinar o modelo
O ideal é dividir o conjunto de dados históricos em 2 grupos: 70% e 30% (ou 90% e 10%, ou o que for melhor para o seu negócio).
Usa-se 70% dos dados para treinar o modelo e os outros 30% são aplicados ao modelo gerado, de forma a verificar se a classificação prevista por ele realmente é a classificação correta. Dessa forma podemos verificar se o modelo tende a funcionar para dados desconhecidos. Essa etapa de validação chamamos de TESTAR o modelo.
Imagine que os 30% de dados no nosso caso correspondem a 10 emails. Se desses 10, o modelo acertou 9, então podemos dizer que a confiabilidade do modelo é de 90%.
Resumindo:
- primeiro, precisamos TREINAR um modelo com base em 70% dos dados históricos;
- depois, precisamos TESTAR se esse modelo consegue prever valores corretos, comparando os valores previstos com os 30% restantes dos dados;
- finalmente, o modelo pode ser usado em produção para PREVER novos resultados.
Classificar um email como SPAM ou NÃO SPAM é um caso clássico de Machine Learning. Obviamente é um caso bem simples e algoritmos de Machine Learning fazem muitos outros tipos de predições, por exemplo:
- qual próximo filme o cliente pode querer assistir?
- qual produto eu devo sugerir pensando na probabilidade do cliente comprar?
- estes sintomas do paciente indicam um tipo de câncer?
- determinada transação financeira pode representar uma fraude?
Já existem uma série de algoritmos de Machine Learning prontos e eles são divididos em 2 categorias principais:
- algoritmos de aprendizagem supervisionados: utilizam dados históricos para prever novos dados (como no exemplo acima);
- algoritmos de aprendizagem não supervisionados: preveem novos dados sem ter dados históricos para se basear.
Mas, começando com o básico, como fica o código que classifica os emails em SPAM ou NÃO SPAM?
Isso fica para o post da semana que vem.  Figura 1 - Dados históricos de emails já classificados em SPAM e NÃO SPAM
Analisando este conjunto de dados, é possível perceber que a grande maioria dos emails com a palavra "Emagrecer" eram SPAM. Normalmente emails que eram enviados para mais de 10 destinatários também eram SPAM. Possuir imagens no corpo do email acaba sendo indiferente.
Então é possível tentar prever se um email é spam ou não.
É exatamente isso que os algoritmos de Machine Learning fazem.
A partir de dados históricos (vários emails recebidos e que já foram classificados em SPAM ou NÃO SPAM) é possível aplicar um algoritmo que tenta extrair regras destes dados, criando um modelo. Chamamos essa etapa de TREINAR o modelo.
Pegamos um novo email então e aplicamos o modelo criado, gerando uma possível classificação. Chamamos essa etapa de PREVER resultados.
Normalmente, não usamos todos os dados históricos para treinar o modelo
O ideal é dividir o conjunto de dados históricos em 2 grupos: 70% e 30% (ou 90% e 10%, ou o que for melhor para o seu negócio).
Usa-se 70% dos dados para treinar o modelo e os outros 30% são aplicados ao modelo gerado, de forma a verificar se a classificação prevista por ele realmente é a classificação correta. Dessa forma podemos verificar se o modelo tende a funcionar para dados desconhecidos. Essa etapa de validação chamamos de TESTAR o modelo.
Imagine que os 30% de dados no nosso caso correspondem a 10 emails. Se desses 10, o modelo acertou 9, então podemos dizer que a confiabilidade do modelo é de 90%.
Resumindo:
Figura 1 - Dados históricos de emails já classificados em SPAM e NÃO SPAM
Analisando este conjunto de dados, é possível perceber que a grande maioria dos emails com a palavra "Emagrecer" eram SPAM. Normalmente emails que eram enviados para mais de 10 destinatários também eram SPAM. Possuir imagens no corpo do email acaba sendo indiferente.
Então é possível tentar prever se um email é spam ou não.
É exatamente isso que os algoritmos de Machine Learning fazem.
A partir de dados históricos (vários emails recebidos e que já foram classificados em SPAM ou NÃO SPAM) é possível aplicar um algoritmo que tenta extrair regras destes dados, criando um modelo. Chamamos essa etapa de TREINAR o modelo.
Pegamos um novo email então e aplicamos o modelo criado, gerando uma possível classificação. Chamamos essa etapa de PREVER resultados.
Normalmente, não usamos todos os dados históricos para treinar o modelo
O ideal é dividir o conjunto de dados históricos em 2 grupos: 70% e 30% (ou 90% e 10%, ou o que for melhor para o seu negócio).
Usa-se 70% dos dados para treinar o modelo e os outros 30% são aplicados ao modelo gerado, de forma a verificar se a classificação prevista por ele realmente é a classificação correta. Dessa forma podemos verificar se o modelo tende a funcionar para dados desconhecidos. Essa etapa de validação chamamos de TESTAR o modelo.
Imagine que os 30% de dados no nosso caso correspondem a 10 emails. Se desses 10, o modelo acertou 9, então podemos dizer que a confiabilidade do modelo é de 90%.
Resumindo:



